
The World Wide Web (WWW) is a globally network of interconnected information elements represented in a standard form using a dialect of SGML called HyperText Markup Language (HTML), using the HyperText Transfer Protocol (HTTP) for the transport of information, employing a uniform addressing scheme for locating resources on the Web called Universal Resource Locator (URL), a set of protocols for accessing named resources over the Web and a growing number of servers that respond to requests from browsers (or clients) for documents stored on those Web servers. In a simple, but not entirely correct, comparison HTML is the information representation (that corresponds to, say, MPEG-2 Video) and HTTP is the information transport (that corresponds to, say, MPEG-2 Transport Stream). Of course MPEG-2 does not have the notion of “hyperlink”.
A summary sequence of the events that led to the creation of the WWW can be described by the following table:
| Year | Name | Description |
| 1989 | Tim Berners-Lee, a physicist working at the Centre Européen pour l’Énergie Nucléaire (CERN) in Geneva, writes a document entitled “Information Management: A Proposal” | |
| 1990 | WWW | The proposal is approved and Tim starts working on a program that would allow linking and browsing text documents. Program and project are called WorldWideWeb |
| 1991 | Line mode browser is developed and WWW is released on CERN machines |
|
| 1992 | HTML HTTP |
There are 26 reasonably reliable servers containing hyperlinked documents. The major technical enablers of the work are HTML and HTTP |
| 1993 | Mosaic | Marc Andreesen and others employees of National Center for Supercomputer Applications (NCSA) in the USA create the first user friendly, “clickable” Internet browser. The browser is given away free for trial to increase the publicity of Mosaic |
| 1994 | Netscape | Marc leaves NCSA to start his own company, first called Mosaic Communications Corp and later Netscape Communication Corporation. The success of the Netscape browser is immediate |
| 1994 | W3C | The immediate success of the WWW triggers the establishment in of the World Wide Web Consortium at MIT. CERN discontinues support of these non-core activities and transfers them to the Institut National pour la Recherche en Informatique et Automatique (INRIA) in France. A W3C centre is hosted later at Keio University in Japan. In recent years W3C has become a major Standards Developing Organisation producing Information Technology standards. |
| 1995 | (March) WWW traffic surpasses ftp traffic | |
| 1997 | The threshold of 1 million WWW servers is crossed |
When Tim Berners-Lee needed a simple way to format web pages, he got inspiration from SGML but that standard did not suit his needs. So he developed the HyperText Markup Language (HTML), a simplified form of SGML that uses a pre-defined standard set of tags. This shows that when IT people address a mass market, they know very well what they must do. I bet that if he had introduced SGML without any standard set of tags, we would not have the billions of web pages that we have in the today’s world .
The basic structure of an HTML document is
<HTML>
<HEAD> Something here </HEAD>
<BODY> Something else here </BODY>
</HTML>
From this example one can see that an HTML document is contained between the pair <HTML> and </HTML> and that an HTML document consists of two main parts: the Head, and the Body, each contained between the pair <HEAD> and </HEAD> and the pair <BODY> and </BODY>, respectively. The Head contains information about the document. The element that must always be present in the Head is the <TITLE> tag and is the one that appears as a ‘label’ on the browser window. A tag that may appear in the HEAD part is <META> and this can be used to provide information for search engines. The Body contains the content of the document with its tags.
Imagine now that I want to create a document that contains the centred and bold title “Address list” and two elements of a list, like this one:
Address list
Employee ID: 0001
- Leonardo Chiariglione
- leonardo@cedeo.net
- 0001
Employee ID: 0002
- Anna Bugnone
- anna@cedeo.net
- 0002
In HTML this can be represented as
<HTML>
<HEAD>
<TITLE>Address list</TITLE>
</HEAD>
<BODY>
<CENTER><B>Address list</B></CENTER>
Employee ID: 0001
<UL>
<LI>Leonardo Chiariglione</LI>
<LI>leonardo@cedeo.net</LI>
<LI>0001</LI>
</UL>
<P>
Employee ID: 0002
<UL>
<LI>Anna Bugnone</LI>
<LI>anna@cedeo.net</LI>
<LI>0002</LI>
</UL>
</BODY>
</HTML>
In this HTML document the pair <CENTER> and </CENTER> indicates that “Address list” should be displayed as centred, the pair <B> and </B> indicates that the character string “Address list” should be displayed as bold, the pair <UL> and </UL> indicates that a bulleted list is included and the pair <LI> and </LI> indicates an item in the list is included between the pair. <P> is an instruction to the interpreter to create a new paragraph.
In the first phases of the web evolution, the IETF managed the development of the HTML “communication standard”, but did it only until HTML 2.0, known as RFC 1866. In the meantime different business players were waging wars among themselves to control the browser market, each trying to define its own HTML “format” by adding its own tags to the language that would only be understood by their browsers, and not by their competitors’. W3C took over the standardisation of HTML of which there is version 4.0 with about 90 different tags and HTML5, of which we will say more later.
Search engines
The large number of servers (already 1 million in 1997 and 100 times more in 1995) containing millions of pages (and now many billions) prompted the development of search engines. In essence a search engine performs 3 functions: crawling, i.e. browsing of the WWW to find web pages; indexing, i.e. storing suitably indexed information found during browsing in a data base; and searching, i.e. responding to a user query with a list of candidate links to web pages extracted from the data base on the basis of some internal logic.
There were several attempts, even before the appearance of the WWW, to create search engines. One of the early successful attempts was Digital Equipment’s AltaVista launched in 1995 at altavista.digital.com, the same year Larry Page and Sergey Brin started the Google project. The AltaVista search service was an immediate success but the Google search engine started in 1998 and based on more powerful research, soon overwhelmed AltaVista (and other search engines as well). AltaVista later became available at www.altavista.com but today that URL leads to the Yahoo search page. Today the search business is highly concentrated in the hands of Google (~2 out of 3 queries), Bing (~1 out of 5 queries) and Yahoo! (~1 out of 10 queries). The search engone business model is invariably based on advertising in the sense that if I type “new houses in Tuscany” it is likely that the search engine will post an ad of a real estate developer next to the search results (probably some general articles related to Tuscany), because I am likely interested in a new house in Tuscany.
If the search engine treats all my queries as independent, the search engine will do a poor job at guessing what I am actually looking and also in displaying relevant ads. So the search engine collects a history of my searches, creates a model of myself in its servers, uses “cookies” in my browser to know that the query is coming from me, and displays more effective responses and ads. All good then? Not really because there are two main concerns. The first is that someone is collecting such detailed information about billions of people and the second that the logic by which search results are displayed is unknown. This is creating apprehension in some – especially European – countries that feel uneasy about so much information being in the hands of such huge global companies that have become virtual monopolies in such important businesses as providing information to peoples’ queries and collecting a growing percentage of money spent on advertising. As a consumer I notice that a search engine is just drawing information from me for free and reselling it to advertisers. Even more seriously I fear that the growing exposure of people to the information – voluntarily – accessed from search engines can shape what people think in the long run.
It is a very complex problem but the root of the problem is that search engine users do not know anything about the logic that drives presentation of information to them. This is correct because that algorithm is what makes a search engine better than the competition. Still, asking to entrustthe brains of billions of people without any scrutiny is too much.
I believe that standards can come to help. I certainly do not intend to suggest “standardisation of search engines”. This makes no sense because it would mean stopping progress in an area that has seen so much progress in the last 20 years. But having a commonly shared understanding of architecture and subsystem interfaces of search engined could help. The layered architecture in Figure 1 below is very general, but it says that a search engine is not a monolith and relies on interfaces between functions at different leyers.
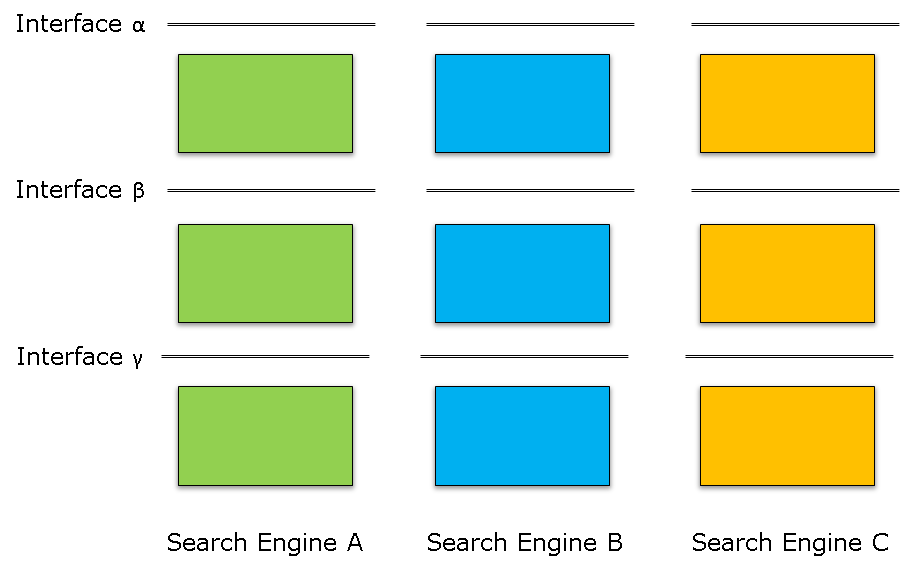
Figure 1 – A layered search engine architecture
Interfaces in the architecture could provide a way for Public Authorities to guide correct behaviours and for search engine users to peek inside their search engines. Much better is to have alternative standard ways of communication such as the one defined by the Publish/Subscribe Application Format.
Collaborative editing
The browser soon became the vehicle to realise in an effective way one old idea of creating documents collaboratively. In 1994 Ward Cunningham developed WikiWikiWeb (in Hawaiian wiki means quick), as a shared database to facilitate the exchange of ideas between programmers. It became the first example of wiki, a website whose pages can be easily edited and linked with a browser by anybody without the need of familiarity with HTML.
Jimmy Wales and Larry Sanger launched the Wikipedia project in 2001, originally as as a wiki-based complementary project for Nupedia, an online encyclopedia project which was not progressing sufficiently fast because it was edited solely by experts. Wikipedia has been an outstanding success. Today (2005) it has articles in 270 languages and number of the articles written in English is about 5 millions. English is the most important language but only 15% of all articles are written in that language. The next language is German with about 5% or all articles.
While admiring the succes of the idea I cannot help but noting that it is odd that an article about a (living) person can be written by a different person. This leads to odd results like the Wikipedia article on Leonardo Chiariglione – not written by me – saying wrong or incorrect things about myself.
XML
Extensible Markup Language (XML) is another derivation of SGML developed by W3C, if not literally, at least in terms of design principles. An XML element is made up of a start tag, an end tag, and data in between. The start and end tags describe the data within the tags, which is considered the value of the element. Using XML, the first employee in the HTML document above could be represented as
<EMPLOYEE>
<ID>0001</ID>
<NAME>Leonardo Chiariglione</NAME>
<EMAIL>leonardo@cedeo.net</EMAIL >
<PHONE>0039 011 935 04 61</PHONE >
</EMPLOYEE>
The meaning of <EMPLOYEE>, <ID>, <NAME>, <EMAIL> and <PHONE>, obvious to a human reader, still do not covey any meaning to a computer, unless this is properly instructed with a DTD. The combination of an XML document and the accompanying DTD gives the “information representation” part of the corresponding HTML document. It does not say, however, how the information should be presented (displayed) because this is the role played by the style sheet. Style sheets can be written in a number of style languages such as Cascading Style Sheet Language (CSS) or eXtensible Style Language (XSL). A style sheet might specify what a web browser should do to be able to display the document. In natural language:
| Convert all | <EMPLOYEE> | tags | to | <UL> | tags |
| Convert all | </EMPLOYEE> | tags | to | </UL> | tags |
| Convert all | <NAME> | tags | to | <LI> | tags |
| Convert all | </NAME> | tags | to | </LI> | tags |
| Convert all | <EMAIL> | tags | to | <LI> | tags |
| Convert all | </EMAIL> | tags | to | </LI> | tags |
| Convert all | <PHONE> | tags | to | <LI> | tags |
| Convert all | </PHONE> | tags | to | </LI> | tags. |
Unlike HTML where “information representation” and “information presentation” are bundled together, in XML they are separate. In a sense this separation of “representation” of information from its “presentation” is also a feature of MPEG-1 and MPEG-2, because a decoder interprets the coded representation of audio and video streams, but the way those streams are presented is outside of the standard and part of an external application. In XML the “external application” may very well be an HTML browser, as in the example above.
On the other hand, MPEG standards do not need the equivalent of the DTD. Indeed the equivalent of this information is shared by the encoder and the decoder because it is part of the standard itself. It could hardly be otherwise, because XML is a very inefficient (in terms of number of bits used to do the job) way of tagging information while video codecs and multiplexers are designed to be bit-thrifty to the extreme.
The work that eventually produced W3C XML Recommendation started in 1996 with the idea of defining a markup language with the power and extensibility of SGML but with the simplicity of HTML. Version 1.0 of the XML Recommendation was approved in 1998. The original goals were achieved, at least in terms of number of pages, because the text of the XML Recommendation was only 26 pages as opposed to the 500+ pages of the SGML standard. Even so, most of the useful things that could be done with SGML, could also be done with XML.
W3C has exploited the description capabilities of XML for other non-textual purposes, e.g. the Synchronized Multimedia Integration Language (SMIL). Like in HTML files, a SMIL file begins with a <smil> tag identifying it as a SMIL file, and contains <head> and <body> sections. The <head> section contains information describing the appearance and layout of the presentation, while the <body> section contains the timing and content information. This is the functional equivalent of MPEG-4 Systems composition. MPEG has also used XML to develop a simplified 2D composition standard called Lightweight Application Scene Representation (LASeR).
XML inherited DTDs from SGML, but it has become apparent that some shortcomings were also inherited, such as the different syntaxes for XML and DTD requiring different parsers, no possibility to specify datatypes and data formats that could be used to automatically map from and to programming languages and no set of well-known basic elements to choose from.
The XML Schema standard improves on DTD limitations. It creates a method to specify XML documents in XML and includes standard pre-defined and user-specific data types. The purpose of a schema is to define a class of XML documents by applying particular constructs to constrain their structure. Schemas can be seen as providing additional constraints to DTDs or a superset of the capabilities of DTDs