
The MPEG machine churns out new standards or amendments at a regular pace, but MPEG is also continuously investigating new standardisation needs. Here is a list of some of the current areas of investigation.
Compact descriptors for video analysis (CDVA).
After the successful completion of the CDVS standard, MPEG is now addressing the following problem: find in a video data base a video resembling the one provided as input. the figure illustrates the problem
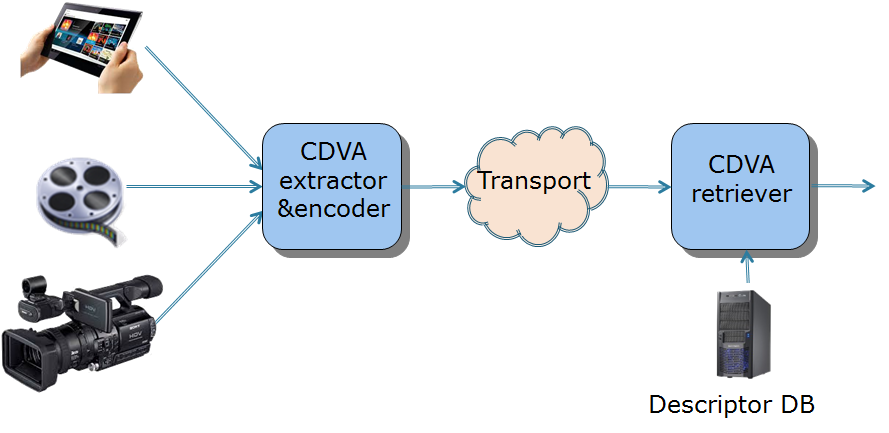
Figure 1 – CDVA for retrieval
A CDVA standard would allow a user to access different video data bases with the guarantee that the descriptors extracted from the input video will be interoperably processed in different video DBs.
Videos of close to 1000 objects/scenes taken from multiples viewpoints have been collected and will be used to test CDVA algorithms submitted in response to a CfP that has been issued at the MPEG 112 meeting.
MPEG has recently issued a CfP on “Compact Descriptors for Visual Search”. The requirements are listed below:
- Self-contained (no other data necessary for matching)
- Independent of the image format
- High matching accuracy at least for special types of image (textured rigid objects, landmarks, and printed documents), and robustness to changes (vantage point, camera parameters, lighting conditions and partial occlusions)
- Minimal length/size
- Adaptation of descriptor lengths for the target performance level and database size
- Ability to support web-scale visual search applications and databases
- Extraction/matching with low memory and computation complexity
- Visual search algorithms that identify and localise matching regions of the query image and the database image, and provide an estimate of a geometric transformation between matching regions of the query image and the database image.
Submissions are due by MPEG 114 (February 2016).
In the future the scope of CDVA for retrieval could be further extended to cover classification as depicted in Figure 2.
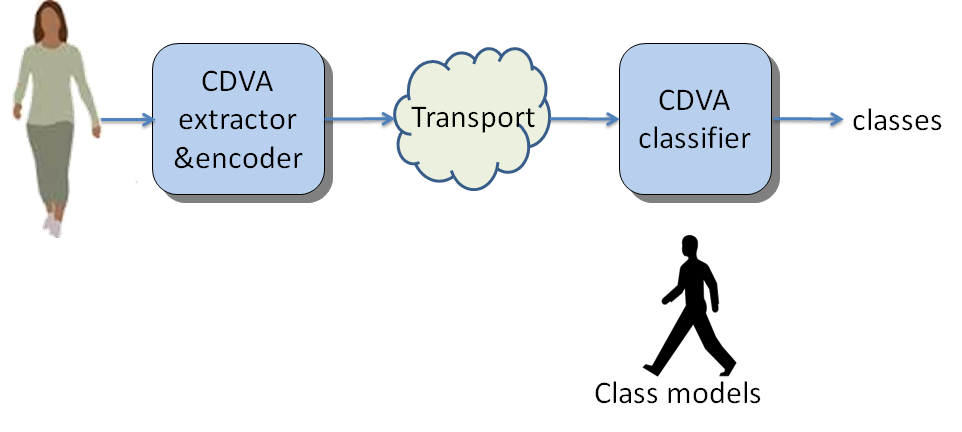
Figure 2 – CDVA for classification
This second type of CDVA technologies could find application for video surveillance where the detection of a person can trigger some process or automotive to alert the driver when an object of a specified nature is in front of the car. CDVA for classification could reverse the current approach where first video is compressed for transmission and then described for use by a classifier, to describe a video and then compress it for transmission.
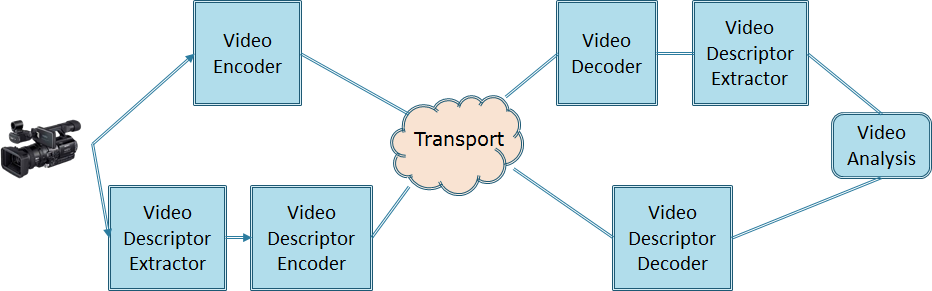
Figure 3 – From compress then describe to describe then compress
Free-viewpoint Television (FTV)
FTV intends to ascertain the existence and performance of two types of technology
- How to compress efficiently a large number (e.g. 100) of signals from cameras aligned on a line or a circle and pointing to the same 3D scene (supermultiview)
- How to reconstruct a 3D scene taken from a virtual point knowning the signals from a limited number (e.g. 10) of cameras
The two figures below depict the two target configurations

Figure 4 – Super Multiview
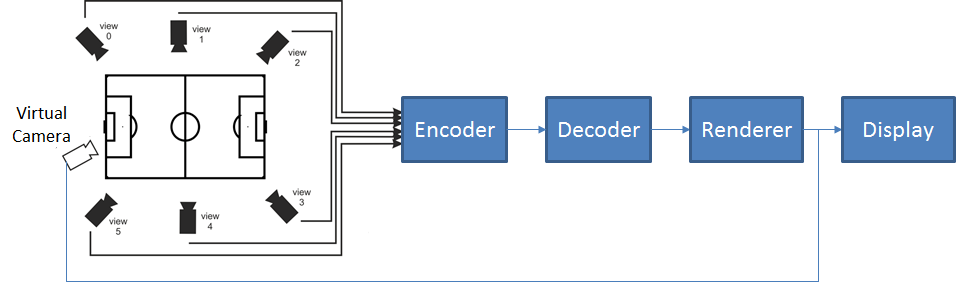
Figure 5 – Free Navigation
MPEG wearables
Wearable devices are characterised by two features
- Can be worn by or embedded in a person or his clothes
- Can communicate either directly through embedded wireless connectivity or through another device (e.g. a smartphone).
Wearable devices allow users to
- Track time, distance, pace and calories via a set of sensors in a T-shirt or on smart shoes
- Wear smart glasses which combine innovative displays with novel gestural movements for interaction
- Wear a pacemaker or a heart rate monitor intelligent band aid.
MPEG has developed the following conceptual model
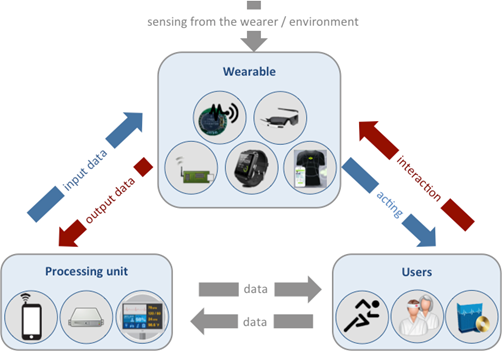
Figure 6 – Conceptual model for MPEG wearable
A wearable sesnses/actos on the environment, communicates with a processing unit and interacts/acts on users. the processing unit can also interact with users.
The scope of MPEG Wearable is to standardise
- The interaction commands from User to Wearable
- The format of the aggregated and synchronized data sent from the Wearable to the Processing unit (represented by red arrows in the figure above);
- A focused list of sensors that the Wearable may integrate.
Media orchestration
Technology supports more and more different capture and display devices, and applications and services are moving towards more immersive experiences. It becomes now possible to create integral experiences by managing multiple, heterogeneous devices over multiple, heterogeneous networks. We call this process Media Orchestration: orchestrating devices, media streams and resources to create such an experience as depicted in Figure 7.
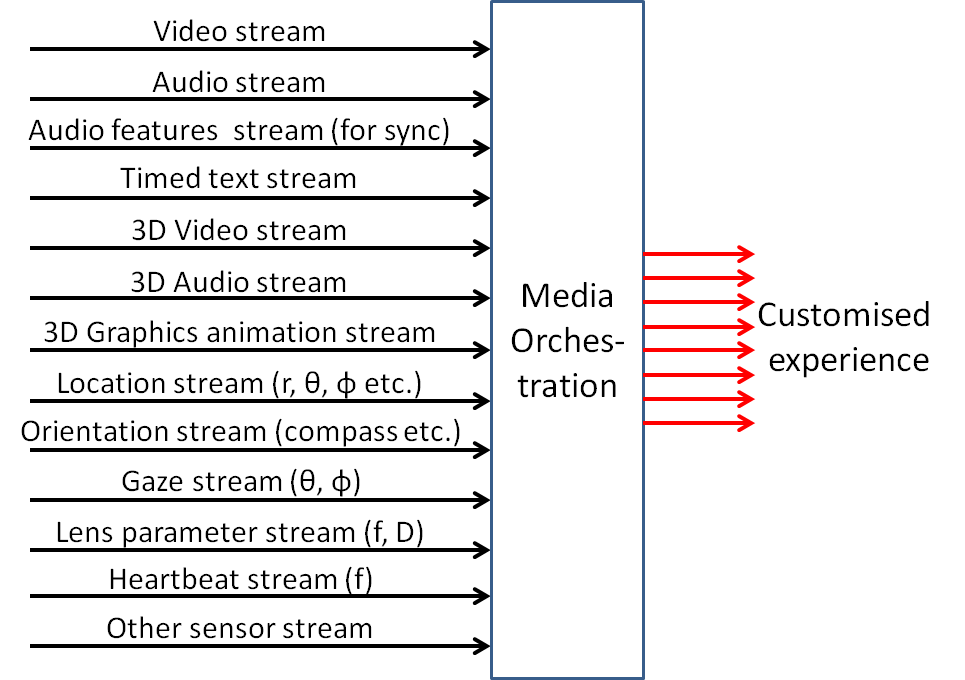
Figure 7 – Media orchestration
Four dimensions have been identified
- Device dimension
- Stream dimension
- Spatio-temporal dimension
- Ingest/rendering dimension
The technical framework distinguishes three independent layers:
- The Functional Architecture,
- Data Model and Protocols
- Data representation and encapsulation
Genome compression
A genome is the code that drives the life of living beings. Genomes are specific of a type of living being and, within it, of a given individual. They are highly structured
- Genomes are composed of chromosomes (46 in the case of humans)
- Chromosomes are composed of genes
- Genes are composed of DNA molecules specific of the gene
- DNAs contain a few tens to a few hundreds nucleotides
- Nucletides are organic molecules (bases)
- There are 4 types of bases depicted in Figure 8.
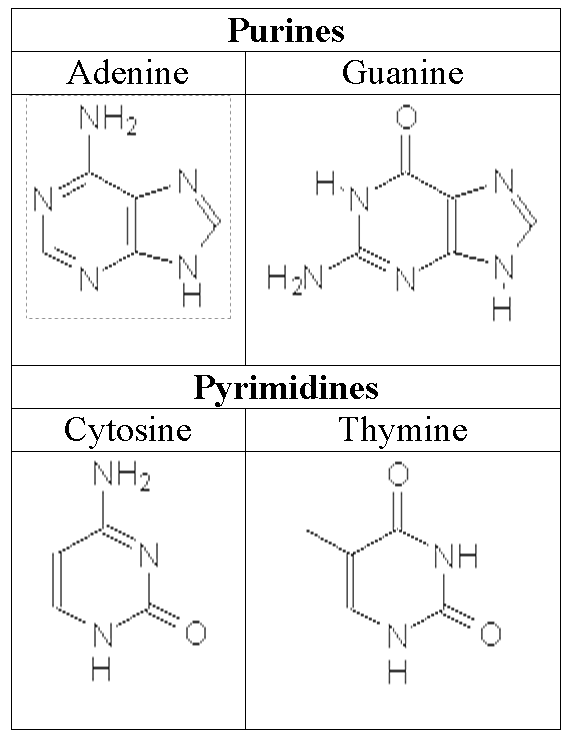
Figure 8 – The 4 molecules composing a DNA
Therefore the genome code is represented by a 4-symbol alphabet. The initials of the 4 bases are used to indicate the symbol. The human genome carries ~3.2 billion symbols.
The ability to read genomes (i.e. converting a genome in an organic sample into a machine-readable sequence) is highly desirable but was very costly until a few years ago. Today high-throughput genome sequencing technology has made sequencing of the genome affordable.

Figure 9 – The genome sequencing process
High Throuput Sequencing (HTS) is opening new perspectives for the diagnosis of cancer and other genetic illnesses. However, genome sequencing generates huge amounts of data, because each base has associated “quality metadata” that describe the quality (i.e. reliability) of the reading of that base. A sequenced human genome can generate several TBytes of data each time.
A genome sequencing machine produces “reads”. Then a computer programs aligns them and produces an assembled “machine readable” genome.
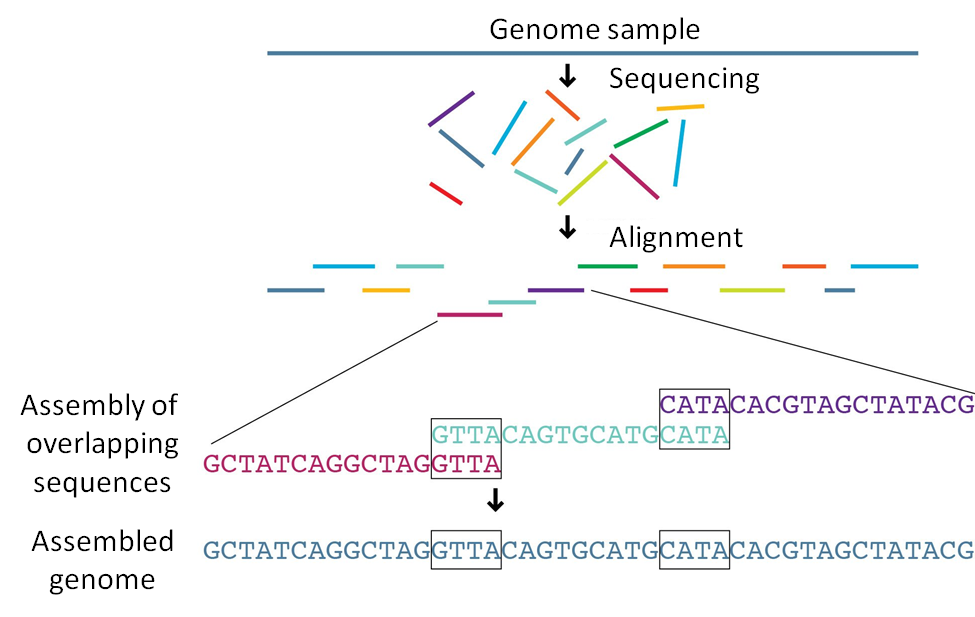
Figure 10 – Genome sequencing by assembling reads
The challenge is to find appropriate algorithms than can reduce the amount of data that need to be stored and make the data easily accessible for a variety of processing.
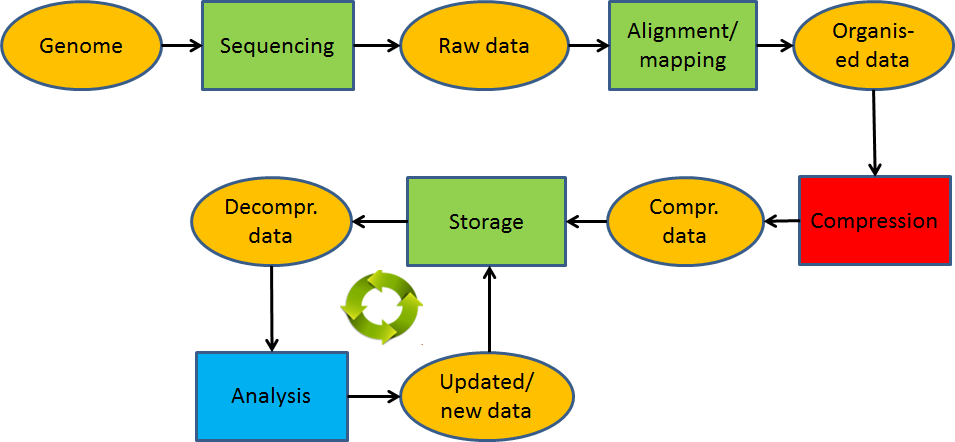
Figure 11 – The genome life cycle
We need to be able to store, access, search and process genome sequencing data efficiently and economically, before these technologies can become generally available in healthcare and medicine. That this is the real roadblock is confirmed by the trend in sequencing data generation cost vs storage and bandwidth costs. The latter will soon be higher that the former.
Media-centric Internet of Things
MPEG has defined “Media-centric Internet of Things (MIoT)” as the collection of interfaces, protocols and associated media-related information representations that enable advanced services and applications based on human to device and device to device interaction in physical and virtual environments. an eventual MIoT standard should allow a system designer to assemble different systems by piecing together MIoTs of appropriate functionality.
The figure below represents the MIoT model
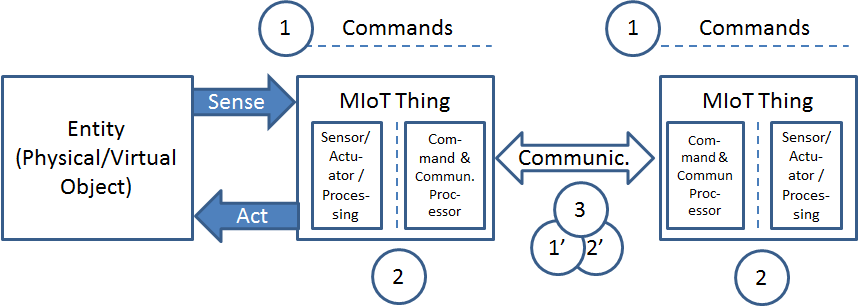
Figure 12 – Media Internet of Things (MIoT) model
where the following definitions apply
- Entity is any physical or virtual object that is sensed by and/or acted on by Things.
- Thing is anything that can communicate with other Things, in addition it may sense and/or act on Entities.
- Media Thing (MThing) is a Thing with at least one of audio/visual sensing and actuating capabilities.
Future Video Coding
MPEG approved HEVC in January 2013 and it may appear premature to consider new a standard that may replace an older standard that is barely being deployed. The reasons for doing so are manyfold:
- Deep-pocketed companies are producing newer generations of video codecs at an accelerated rate
- Mobile is a great way of consuming video and paradigms of the TV age may no longer apply
- New media types are appearing or just becoming more prominent and the coding environment need not stay the same
- Around 2020 a standard for new generation mobile networks (5G) is expected and a new video coding standard for mass consumption of video on mobile is a good fit
- …
At this point it is time to make an assessment of the path trodden by MPEG in its quarter-of-century efforts at compressing video. This is represented by the table below
| Base | Scalable | Stereo | Depth | Selectable viewpoint | |
| MPEG-1 Video |
~VHS |
– |
– |
– |
– |
| MPEG-2 Video |
2Mbit/s |
-10% |
-15% |
– |
– |
| MPEG-4 Visual |
-25% |
-10% |
-15% |
– |
– |
| MPEG-4 AVC |
-30% |
-25% |
-25% |
-20% |
5/10% |
| HEVC |
-60% |
-25% |
-25% |
-20% |
5/10% |
|
? |
? |
? |
? |
? |
? |
In the “Base” column percentage numbers refer to compression improvement compared to the previous generation of compression technology. The percentage numbers in the “Scalable”, “Stereo” and “Depth” columns refer to compression improvement compared to the technology on the immediate left. “Selectable viewpoint” refers to the ability to select and view an image from a viewpoint that was not transmitted. The last row only contains questions marks because it refers to what, potentially, can be done in a future that we do not know, but that we can well create to ourselves.
So far MPEG has produced 5 generations of video coding standards. It is the right time to ask ifit is possible to establish a comparison between the bitrates handled by MPEG video and audio codecs and the bitrates used by the eye/ear-to-brain channel.
The input bandwidth to human sensors are
- Eyes: 2 channels of ~430–790 THz
- Ears: 2 channels of ~20 Hz – 20 kHz
The human body uses a single technology (nerve fiber) to connect sensors to the brain. Transmission of information happens by means of trains of pulses at the rate of ~160 spikes/s (every 6 ms). Assuming that 16 spikes make a bit: 1 nerve carries ~10 bit/s, the bitrates to the brain are
- From 1 eye: 1.2 M fibers transmit ~12 Mbit/s
- From 1 ear: 30 k fibers transmit ~0.3 Mbit/s