| Previous chapter | Next section | Next chapter | |
| ToC | Digital Media Do More | Open Source Software | Digital Media For Machines |
A very general way of classifying information is based on its being structured or unstructured, i.e. on its appearing or being organised according to certain rules. Characters are a special form of structured information because they are the result of mental processes that imply a significant amount of rationalisation. Characters have been one of the first types of structured information that computers have been taught how to deal with. Represented as one (or more than one) byte, characters can be easily handled by byte-oriented processors.
At the beginning, characters were confined within individual machines because communication between computers was still a remote need. In those days, memory was at a premium and the possibility of a 70% saving, thanks to the typical entropy value of structured text (a value that is usually obtained when zipping a text file), should have suggested more efficient forms of character representation. This did not happen, because the processing required to convert text from an uncompressed to a compressed form, and vice versa, and to manage the resulting variable length impacted on a possibly even scarcer real estate: CPU execution. In the early days of the internet the need to transmit characters over telecommunication links arose but, again, the management of Variable Length Coding information was a deterrent. SGML, a standard developed in the mid 1980s, was designed as a strictly character-based standard. The same was done for XML more than 10 years later, even though progress of technology could have allowed bolder design assumptions.
At an appropriate distance, a picture of the Mato Grosso or the sound coming from a crowd of people can be considered as unstructured. Depending, however, on the level at which it is assessed, information can become structured: the picture of an individual tree of the Mato Grosso or an individual voice coming from a crowd of people do represent structured information.
As humans are good at understanding highly complex structured information, one of the first dreams of Computer Science (CS) was endowing computers with the ability to process information in picture or sound signals in a way that is comparable to humans’ abilities. Teaching computers to understand that information proved to be a hard task.
Signal Processing (SP) has traditionally dealt with (mostly) digital pictures and audio (other signals like seigmograms, too, have been given a lot of attention for obvious reasons). Some Computer Science tools have also been used to make progress in this field of endeavour. Unlike the CS community, the SP community had to deal with huge amounts of information: about 4 Mbit for a digitised sheet of paper, at least 64 kbit/s for digitised speech, about 1.5 Mbit/s for digitised stereo sound, more than 200 Mbit/s for digital video, etc. To be practically usable, these large amounts of bits had to be reduced to more manageable values and this required sophisticated coding (compression) algorithms that removed irrelevant or dispensable information.
In the early days, transmission was the main target application and these complex algorithms could only be implemented using special circuits. For the SP community, the only thing that mattered were bits, and not just “static” bits, as in computer “files”, but “dynamic” bits, represented by the word “bitstream”.
It is worth revisiting the basics of picture and audio compression algorithms keeping both the SP and the CS perspectives in mind. Let’s consider a set of video samples and let’s apply an algorithm – e.g. MPEG-1 Video – to convert them into one or more sets of variables. We take a macroblock of 2×2 blocks of 8×8 pixels each and we calculate one motion vector, we add some other information such as position of the block, etc. and then we apply a DCT to each (differences of) 8×8 pixel blocks. If we were to use the CS approach, all these variables would be tagged with long strings of characters (remember the verbose VRML) and the result would probably be more bits than before. In the SP approach, however, the syntax and semantics of the bitstream containing VLC-coded Motion Vectors and DCT coefficients is standardised. This means that the mapping between the binary representation and the PCM values at the output (the “dcoding process”) is standardised, while the equivalent of the “tagged” representation that exists in a decoder implementation is not.
The CS community did not change its attitude when the WWW was invented. In spite of the low bitrate of the communication links available in the early years of the web, transmission of an HTML page was (and is) done by transmitting the characters in the file. Pictures are sent using JPEG for photo-like pictures and GIF/PNG for graphic pictures (even though many authors do not understand the different purposes of the formats and use one format for the other purpose). JPEG has been created by the SP community and applies compression; Graphics Interchange Format (GIF) has been created by the CS community and only applies a mild lossless compression. Portable Network Graphics (PNG), a picture representation standard developed by the W3C, applies little compression, probably because users were not expected to be concerned with their telephone bills.
This means that the world has been misusing the telecommunication infrastructure for years by sending about three times more character information than should have been strictly needed using a simple text compression algorithm. Not that the telco industry should complain about it – the importance of its role is still somehow measured by how many bits it carries – but one can see how resources can be misused because of a specific philosophical approach to problems. The transmission of web pages over the “wireless” internet used to be of interest to the telcos because bandwidth used to be narrow and for some time there were companies offering solutions that allowed sending of “compressed” web pages to mobile phones (when there were too few bit/s on the air). Each of the solutions proposed was proprietary, without any move to create a single standard, so when the hype subsided (because available bandwidth improved) those incompatible solutions melted like snow in a hot day.
A similar case can be made for VRML worlds. Since these worlds are mostly made of synthetic pictures, the development of VRML was largely made by representatives of the CS community. Originally it was assumed that VRML worlds would be represented by “files” stored in computers, so the standard was designed in the typical CS fashion, i.e. by using text for the tags, and long text at that because the file “had to be human readable”. This resulted in exceedingly large VRML files and their transmission over the Internet was not practical for a long time. The long downloading time of VRML files, even for simple worlds, was one of the reasons for the slow take off of VRML. Instead of working on reducing the size of the file by abandoning the text-based representation, so unsuitable in a bandwidth-constrained network environment, the Web3D Consortium (as VRLM is now called) developed an XML-based representation of its VRML 97 standard, which keeps on using long XML tags.
One of the first things MPEG, with its strong SP background, did when it used VRML 97 as the basis of its scene description technology, was to develop a binary representation of the VRML textual representation. The same was done for Face and Body Animation (FBA) and indeed this part of the MPEG-4 standard offers another good case study of the different behaviour of the CS and SP communities. As an MPEG-4 synthetic face is animated by the value of 66 parametres, a transmission scheme invented in the CS world could code the FAPs somewhat like this:
(type joy, intensity 7), viseme (type o, intensity 5), open_jaw (intensity 10), …, stretch_l_nose (intensity 1), …, pull_r_ear (intensity 2)
where the semantics of expression, joy, etc. is normative. Transmission would simply be effected by sending the characters exactly as they are written above. If the coding is done in the SP world, however, the first concern is to try and reduce the number of bits. One possibility would be to group the 66 FAPs in 10 groups, where the state of each group is represented with 2 bits, e.g. with the following meaning:
| 00 | no FAP transmitted |
| 11 | all FAPs in the groups are transmitted with an arithmetic coder |
| 01 | some FAPs, signalled with a submask, transmitted with an arithmetic coder |
| 10 | some FAPs, signalled with a submask, interpolated from actually transmitted FAPs |
Another interesting example of the efforts made by MPEG to build bridges between the CS and SP worlds is given by XMT. Proposed by Michelle Kim then with IBM Research, XMT provided an XML-based textual representation of the MPEG-4 binary composition technology. As described in Figure 1, this representation accommodated substantial portions of SMIL and Simple Vector Graphics (SVG) of W3C, and X3D (the new format of VRML). Such a representation could be directly played back by a SMIL or VRML player, but could also converted to binary to become a native MPEG-4 representation that could be played by an MPEG-4 player.
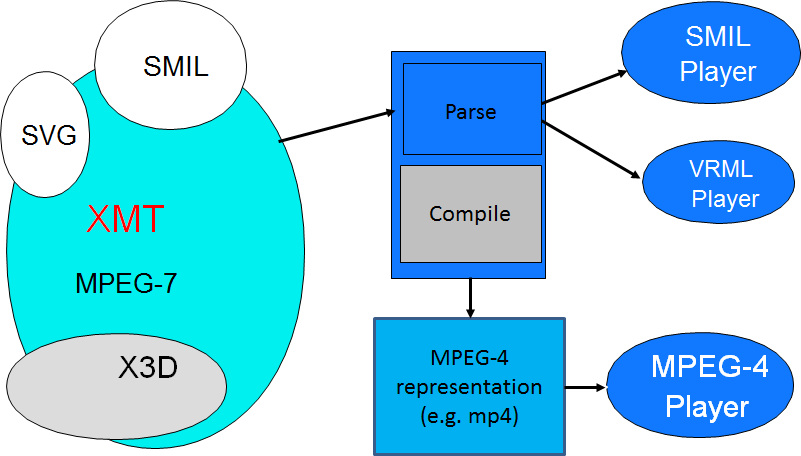
Figure 1 – XMT framework
As described later in the MPEG-7 section, BiM was another bridge between the character-based and the binary world. BiM was designed as a binariser of an XML file to allow bit-efficient representation of Descriptors and Description Schemes, but could also be used to binarise any XML file. For this reason, it was been moved to MPEG-B part 1 as we will see later.
| Previous chapter | Next section | Next chapter | |
| ToC | Digital Media Do More | Open Source Software | Digital Media For Machines |