| Previous chapter | Next section | Next chapter | |
| ToC | Software And Communication | MPEG-7 – Inside | More About Rights and Technologies |
The Life in ISO page tells about my efforts in overcoming the many obstacles on the road to establishing Subcommittee 29 (SC 29), because of the “lupissimus” nature of the organisations operating under the ISO folds, and make it the video, audio, multimedia and hypermedia coding Sub-Committee. I did this because I felt the need of a higher-level group than a WG with the task to plan, organise and shield – yes, again – the work of the technical groups against the wolves ambulating in circle. I had great hopes that SC 29 would deal with these issues with the same aggressive – in a positive sense, of course – spirit as MPEG.
In 1993, two years after its establishment, I had begun to inquire what would be the future of SC 29. The SC 29 meeting in Seoul, on the three days following the MPEG meeting, provided the opportunity to make a proposal, triggered by the growing excitement that the television industry of that time, especially the cable television industry, was feeling because MPEG-2, with its ability to put more than 5 times more programs in their analogue transmission channels, was becoming real. My reasoning was: if people will be confronted with an offering of 500 simultaneous programs and if the indexing of programs remained the same as used with a few programs, then how on earth would consumers ever become aware of what is on offer?
At the Seoul meeting, the Italian National Body made a number of proposals. One of them recited:
the success of future multimedia services/applications can be assured only if a scalable man/service interface is defined that is capable to deal with the simpler services/applications of today and be easily upgraded to deal with the sophisticated multimedia ones in the future.
At that time I had no intention of getting MPEG in this kind of work – the group had enough to chew on its own with MPEG-2 and MPEG-4 – so I proposed that MHEG make a study on the subject and report back at the following meeting one year later (I know, this does not look very much “internet-like”, but that was 1993). With my engagement in DAVIC starting immediately after that meeting, I hope I can be at least understood if not excused for having no time to follow the work that MHEG was expected to do during 1994. That was a mistake, because at the Singapore meeting one year later the MHEG chair reported that the study had not been made, yet. So they were given another year. After the Singapore meeting my life became, if possible, even more hectic and the matter then fell into oblivion.
With my departure from DAVIC in December 1995, I had enough time to rethink the role of MPEG and at the Florence meeting in March 1996, I revisited my 30-month old proposal and raised it within MPEG, of course augmented with the experience gained during that time span. At first the proposal did not go through very well with the members. At that time the MPEG community was still massively populated with compression experts and the idea of dealing with “search interfaces” was too alien to them. With perseverance, however, a core group of people understanding and supporting the new project began to form and at the Chicago meeting in September/October 1996 the group had come to the conclusion that this was indeed something MPEG had to do.
Unlike what MPEG had done until that time, the next work item would deal with “description” of audio and video. Description is nothing else than just another form of information representation, and SGML and XML already provide the means to represent textual descriptions. The real difference was that, in the standards that MPEG had developed or was planning to develop, information was represented for the purpose of feeding it to human beings and it was natural that the fidelity criterion for the representation should be based on a measure of “original vs. decompressed” distortion. A movie is still seen and heard by human eyes and ears, and therefore it must look and sound “good”, Signal to Noise Ratio (SNR) in its many forms being one measure somehow related to how much a particular piece of content looks similar to the original and hence “good” (from the technical quality viewpoint). On the other hand “descriptions” were meant for use by machines that could only process information if it was in a form understood by them with the ultimate goal of showing something to the end user that might be only related to the descriptions. In the process, the original emphasis on “interfaces” was – rightly – lost and the core technology became “digital representation of descriptors”. The title of the standard, however, is “Multimedia Content Description Interface” and still makes reference to interfaces.
Finding the “what” had been – so to speak – easy, even though it had taken some time to get there. Finding the MPEG “number” to identify it, not equally so. The numbers of previous MPEG standards had been assigned in a sequential logic that a combination of technology, politics and other factors had disrupted. One school of thought leaned toward MPEG-8, the obvious sequential logic extension to powers of 2, while some others wanted to resume the normal order and call it MPEG-5. I personally favoured the former, but one morning Fernando Pereira, who had been my Ph.D. student at CSELT in the late 1980s and had been attending MPEG since the official start of MPEG-4 in late 1993, called me and proposed MPEG-7. The number stuck.
The year 1997 was largely spent working out the requirements, going through the usual steps of identifying applications. One major application example of MPEG-7 is multimedia information retrieval systems, i.e. systems that allow for quick and efficient search of various types of multimedia information of interest to a user in, say, a digital library. When storing the data themselves, also the descriptions – the metadata – would be stored in such a way that searches could be carried out.
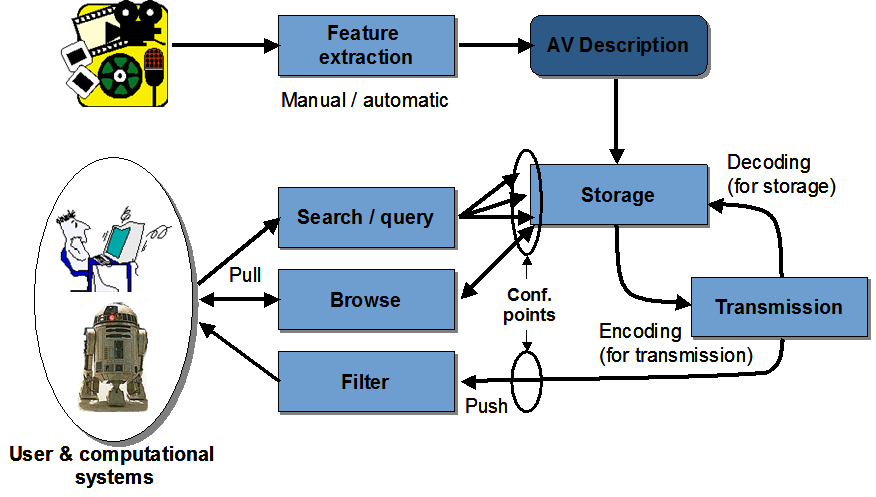 Figure 1 – Search using MPEG-7
Figure 1 – Search using MPEG-7
Another example is filtering in a stream of audio-visual content descriptions, the famous “500-channel” use case in which the service provider would send, next to the TV programs, appropriate descriptions of them. A user could instruct his set top box or recording device to search those programs that would satisfy his preferences. In this way the device would scan for, say, all types of news with the exclusion of, say, sports.
A third example is made of applications based on image understanding techniques, such as those found in surveillance, intelligent vision, smart cameras, etc. A sound sensor would produce sound not in the form of samples but, say, loudness and spectral data, and an image sensor might produce visual data not in the form of pixels but in the form of objects, e.g. physical measures of the object and time information. These could then be processed to verify if certain conditions were met and, in the positive case, an alarm bell would ring.
The last example in this list is media conversion, such as one that would be used at an infopoint. Depending on user queries and the type of user device, the system would generate responses by converting elements of information from one type to another using the semantic meaning of each object.
The examples given confirm the original assumptions: in MPEG-7 audio and visual information would be created, exchanged, retrieved and re-used by computational systems where humans would not necessarily deal directly with descriptors, but only consume the result of the processing effected by an application. Humans would probably make queries in manifold forms such as by using natural languages or by hand-drawing images, or by selecting models or by humming. The computer would then convert the queries into some internal form that would be used to execute whatever MPEG-7-based processing was needed to provide an answer. But both the input and output processing would be outside of the standard, as MPEG is only concerned by “interfaces”.
Here are some examples of how queries could be formulated for different types of media.
| Media Type | Query Type |
| Images | Draw colour and texture regions and search for similar regions. |
| Graphics | Sketch graphics and search for images with similar graphics. |
| Object Motion | Describe motion of objects and search for scenes with similarly moving objects. |
| Video | Describe actions and retrieve videos with similar actions. |
| Voice | Use an excerpt of a song to retrieve similar songs/video clips. |
| Music | Play a few notes and search for list of musical pieces containing them. |
The first view of MPEG-7 was very much driven by the signal processing background of most MPEG members and addressed the standard descriptions of some low-level audio and video features. Video people would think of shape, size, texture, colour, movement (trajectory), position, etc. Audio people would think of key, mood, tempo, tempo changes, position in sound space, etc. But what about a query of the type: “a scene with a barking brown dog on the left and a blue ball that falls down on the right, with the sound of passing cars in the background”? To provide an answer, it was clear that the system had to make use not only of low-level descriptors, but also of higher-level information as depicted in Figure 2.
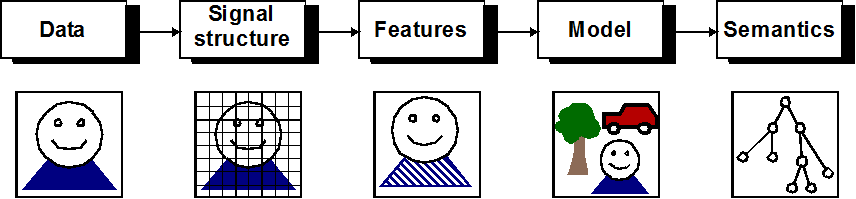
Fig. 2 – Information levels in MPEG-7
Examples of information elements for each levels are given in Tab. 1.
Table 1 – Information elements for each level
| Data | Signal Structure | Features | Model | Semantics |
| Images |
Regions | Color | Clusters |
Objects |
| Video |
Segments | Texture | Classes | Events |
| Audio |
Grids | Shape | Collections | Actions |
| Multimedia | Mosaics | Motion | Probabilities | Video |
| Formats |
Relationships (Space-time) | Speech | Confidences | People |
| Layout | Timbre | Relationships | ||
| Melody |
This recognition triggered a large-scale invasion of IT world experts into MPEG, in addition to a smaller-scale invasion of experts from another field, metadata, a term now fashionable and meaning data about data, including data that assist in identifying, describing, evaluating and selecting information elements that metadata describe. At the time MPEG-7 was starting, some metadata “initiatives” were already under way or starting, such as the Dublin Core, P/META, SMPTE/EBU, etc. All these, however, were sectorial in the sense that they were driven by a specific industry.
While the requirement work was progressing, MPEG started an action to acquire audio and visual data that could be used to test submissions in the competitive phase and to conduct core experiments in the subsequent collaborative phase. The MPEG-7 content set, as assembled at the Atlantic City meeting in October 1998, was composed of three main categories: Audio (about 12 hours), Still images (about 7000 images, 3000 of which were trademark images from the Korean Industrial Property Office) and Video (about 13 hours). Other types of content were assembled in subsequent phases. The MPEG-7 content set also offered the opportunity for MPEG to have direct experience of “licensing agreements” that right holders made for the use of audio and visual test material.
Licensing terms for content used in the development of MPEG standards had varied considerably. The CCIR video sequences, obtained through the good offices of Ken Davies, were released “for development of MPEG standards”. The MPEG-1 Audio sequences were extracted from the so-called EBU SQAM CD and were affected by similar conditions. Most of the MPEG-2 Video sequences – high-quality video clips at TV resolution – had stricter usage conditions. Also most MPEG-4 sequences had well-defined conditions. For the first time, use of the MPEG-7 content set was regulated by an agreement drafted by a lawyer and that had to be signed by those who wanted to use that content.
The well-tested method of producing a Call for Proposals (CfP) to acquire relevant technology was also used this time. The MPEG-7 CfP was issued in October 1998 at the Atlantic City meeting and the University of Lancaster, via the good offices of Ed Hartley, the the UK HoD at that time, kindly hosted a meeting of the “MPEG-7 Test and Evaluation” AHG at the following February 1999 meeting. The total number of proposals, submitted by some 60 parties, was almost 400 and the number of participants was almost as large as the one of a regular MPEG meeting.
After an intense week of work, during which fair comparisons by experts between submissions was made – without subjective tests for the first time, in keeping with the “computer-processable data” paradigm – the technical work could start.
It took some time to give a clean structure – no longer precisely one and trine this time – to the MPEG-7 standard. Eventually it was agreed that there would be a standardised core set of Descriptors (D) that could be used to describe the various features of multimedia content. Purely Visual and purely Audio Descriptors would be included in the Visual and Audio parts of the standard, respectively. Then pre-defined structures of Descriptors and their relationships, called Description Schemes (DS) would be included in the Multimedia Description Schemes part of the standard. This part would also contain Ds that were neither Visual nor Audio. DSs would need a language – called Description Definition Language (DDL) – so that DSs and, possibly, new Ds could be defined. Lastly there would be a bit-efficient coded representation of descriptions to enable efficient storage and fast access, along with a “Systems” part of the standard, that would also provide the glue holding together all the pieces.
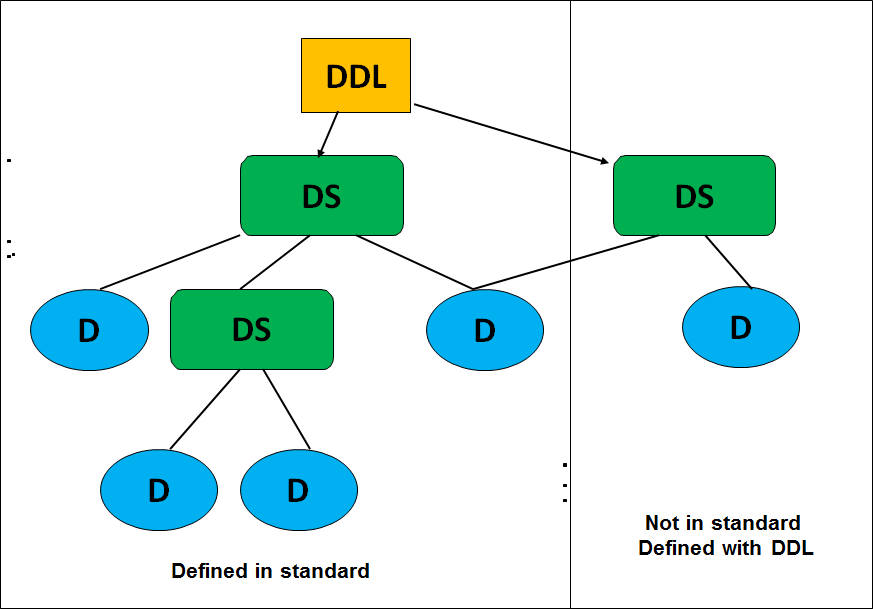
Figure 3 – Descriptors, Description Schemes and Description Definition Language in MPEG-7
Work progressed smoothly until the July 1999 meeting in Vancouver. At that time it was realised that the organisation of the group, based on Requirements, DMIF, Systems, Video, Audio, SNHC, Test, Implementation Studies and Liaison, that had remained unchanged since July 1996, was no longer a good match to the new context. One viewpoint was that DSs could be considered as an extension of the MPEG-4 multimedia composition work and responsibility for it could have been taken over by the Systems group. On the other hand, during all of the MPEG-4 development there had been a hiatus, not really justified by technical reasons, between the Systems and DMIF work that had led to the publication of two different parts of the standard, while they could have been combined or published more rationally with a different split of content. If this rift were to be mended, the merger of the Systems and DMIF groups would be justified.
After a very long discussion at the Chairs meeting – helped by the long summer days of Vancouver – it was concluded that the best arrangement would be to bring the Systems and DMIF work together and to establish a new group called Multimedia Description Schemes (MDS). Philippe Salembier of the Polytechnic University of Catalunya was appointed as chairman of that group. At the same meeting the DSM group, one of the earliest MPEG groups, and the originator of the DSM-CC and DMIF standards, was disbanded after 10 years of service.
Several solutions were available when the DDL development started but none of them was considered stable enough. The initial decision made by MPEG was to develop its own language whilst keeping track of W3C’s XML Schema developments. The idea was to use the work done in W3C if ready, but to have a fallback solution in case the W3C work was delayed. In April 2000 the improved stability of XML Schema Language, its expected widespread adoption, the availability of tools and parsers and its ability to satisfy the majority of MPEG-7’s requirements, led to the decision to adopt XML Schema as the basis for the DDL. However, because XML Schema was not designed specifically for audio-visual content, certain specific MPEG-7 extensions had to be developed by MPEG.
MPEG-7 obviously needed its own reference software, called eXperimentation Model (XM) software and Stefan Herrmann of the University of Munich was appointed to oversee its development. The XM was the simulation platform for the MPEG-7 Ds, DSs, Coding Schemes (CS), and DDL. MPEG-7 followed the path opened by MPEG-4 for reference software with some adjustments. Proponents did not have to provide reference software if the rest of the code utilised an API documented and supported by a number of independent vendors or if standard mathematical routines such as MATLAB were involved, or if it was possible to utilise publicly available code (source code only) that could be used without any modification. Also, as was already the case of MPEG-4, there was no obligation to provide very specific feature extraction tools.
The MPEG-7 standard was approved at the Sydney meeting in July 2001, at the longest ever MPEG meeting that approached 24:00. At that time the standard included the 3 parts Systems, DDL, Video, Audio and MDS. Very soon Reference Software (part 6) and Conformance (part 7) were published. Other MPEG-7 parts are Extraction and Use of MPEG-7 Descriptions, Profiles, Schema definition, Profile schemas, Query Format and Compact Descriptors for Visual Search. More about the last two later.
| Previous chapter | Next section | Next chapter | |
| ToC | Software And Communication | MPEG-7 – Inside | More About Rights and Technologies |