Unlike MPEG-1, where a reference model strictly need only consider the decoder, the full extent of the MPEG-2 standard requires consideration of the complete chain from source to destination for the DSM-CC part. The figure below gives a schematic representation of the scope of the MPEG-2 standard. The Source, however, is still not part of the standard.
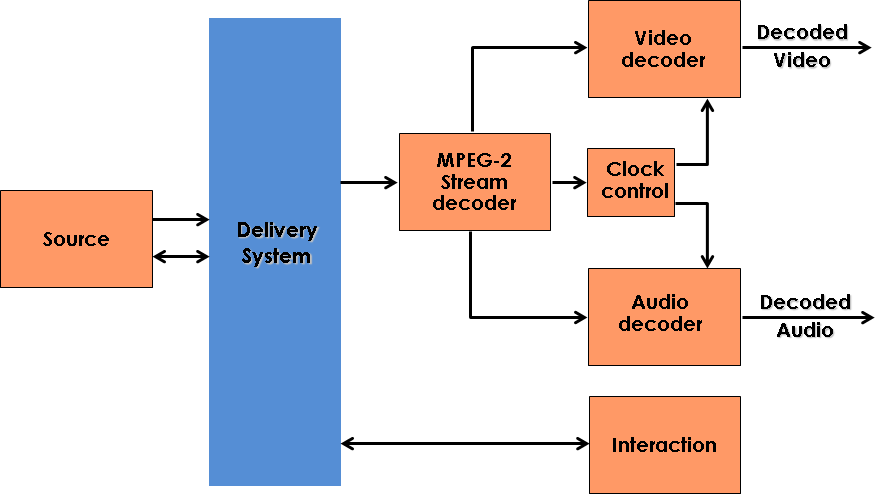
Figure 1 – Model of the MPEG-2 standard
The Demultiplexer, Video and Audio decoding blocks correspond to part 1, 2 and 3 (or 7) of ISO/IEC 13818. The DSM-CC block, not in the MPEG-1 model, is specified in part 6. Additionally part 9 provides the jitter specification of the interface between the receiver and the delivery system. Part 4 is conformance testing for parts 1, 2, 3 and 7. Similarly part 5 is the Reference Software for parts 1, 2, 3 and 7 (no reference software exists for part 6). Part 10 is conformance testing of DSM-CC. A part 11 has been added later providing specification for an extension of conditional access functionality.
MPEG-2 Systems is a great piece of engineering work designed to satisfy a broader range of multi-industry requirements than any other groups had ever tried to deal with before in a standards committee. The figure below illustrates the basic multiplexing approach for a television program composed of a single video stream and a single audio stream.
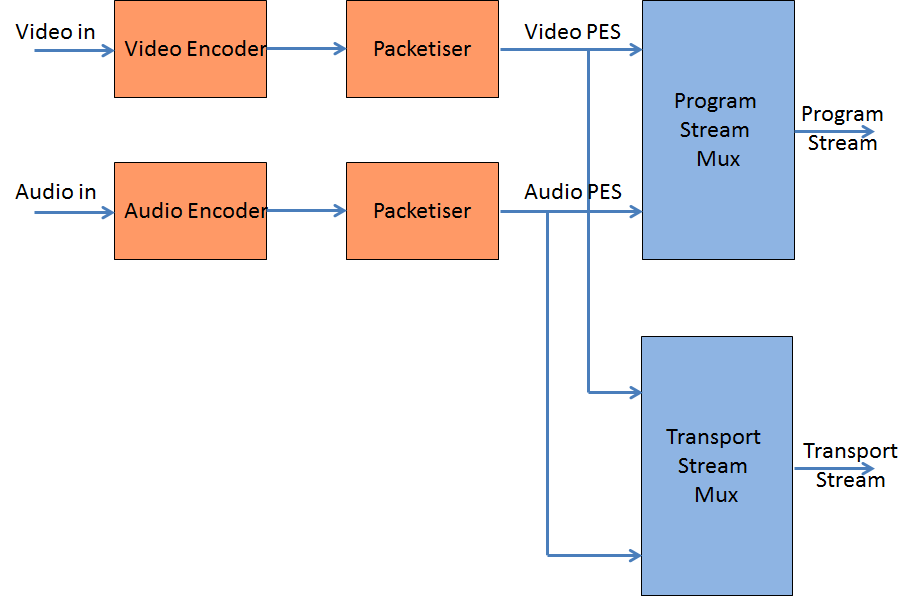
Figure 2 – Model of MPEG-2 Systems
The video and audio data are encoded according to MPEG-2 Video and MPEG-2 Audio or AAC, and systems level information is added to the resulting compressed streams. These streams in packetised form are called Packetised Elementary Streams (PES). The PESs can then be further combined to form either a PS or a TS.
The PS results from combining one or more PESs, all having a common time base, into a single stream, much like the MPEG-1 Systems Multiplex. The PS is designed for use in the same relatively error-free environments and is suitable for software processing applications. PS packets may be of variable and relatively great length.
The TS combines one or more PESs with the same or different time bases into a single stream, a requirement for the carriage of more than one TV programs that in general have been produced with independent clocks. The TS is designed for use in environments where errors are likely, such as storage or transmission in lossy or noisy media. TS packets are 188 bytes long. This choice was made, for lack of better reasons, because at the time it was thought that having a packet length related to ATM Adaptation Layer 1 (AAL1) packet lengths (188=4×47) expected to be used for real-time video transmission, would be an advantage.
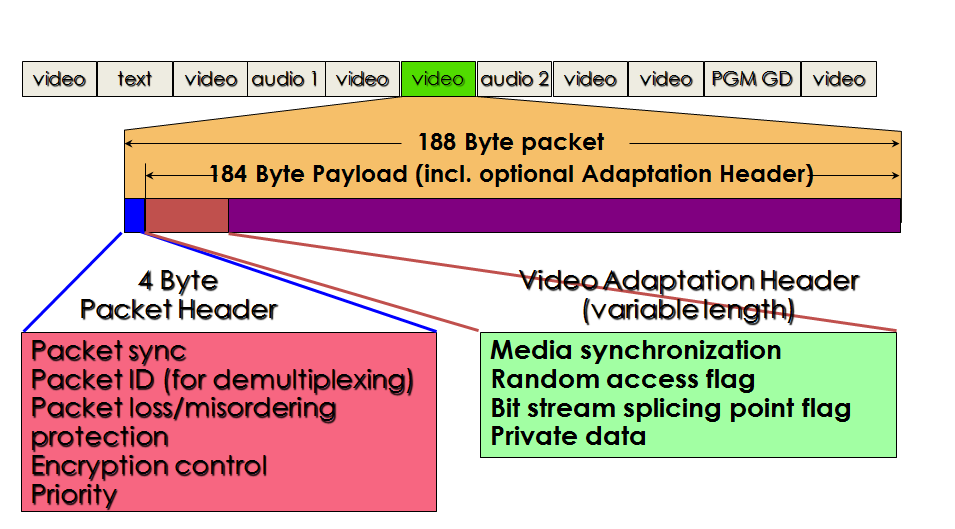
Figure 3 – Structure of an MPEG-2 TS packet
Part 2 extends MPEG-1 by adding several new tools. The most important ones are those that encode interlaced video. When video is already in progressive form, MPEG-2 Video coding falls back to MPEG-1 Video. Exploitation of interlace information provides an improvement of compression efficiency of about 20%. MPEG-2 Video also provides tools for various types of scalability, namely SNR and spatial scalability. SNR scalability is a functionality that is provided by multiple layers such that an enhancement layer carries DCT coefficients quantised with improved accuracy. In spatial scalability there is a basic layer and an enhancement layer. The latter carries information that can be used to improve the spatial definition of the picture of the basic layer.
Part 3 extends MPEG-1 Audio from the stereo to the multichannel case while preserving backwards compatibility with MPEG-1 Audio. This means that an MPEG-1 Audio decoder is able to extract the stereo part from an MPEG-2 Audio bitstream. The opposite is also true. An MPEG-2 Audio decoder is capable of decoding an MPEG-1 Audio bitstream. MPEG-2 Audio also provides an extension to lower sampling-frequency for MPEG-1 Audio.
Parts 4 and 5 correspond to those of MPEG-1: Conformance and Software Simulation.
Part 6 has the title “Digital Storage Media Command and Control (DSM-CC)” and supplies protocols to establish audio-visual sessions on heterogeneous networks (this is the User to Network part of the standard) and to control audio-visual streams in both interactive and broadcast environments (this is the User to User part of the standard). For interactive environments, the DSM-CC User-to-User protocol allows clients to access a collection of distributed objects (such as files, directories and streams) located on remote servers. For broadcast environments, the DSM-CC User-to-User Object Carousel protocol allows simultaneous access to broadcast objects by various clients (see Fig. 3)).
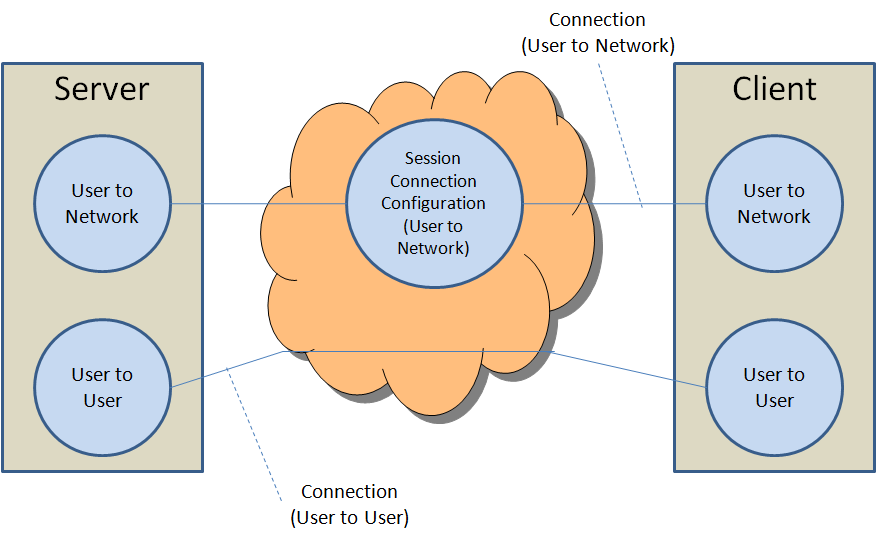
Figure 3 – The DSM-CC model
In the DSM-CC model, a stream is sourced by a Server and delivered to a Client, both considered to be Users of the DSM-CC network. Additionally DSM-CC defines a logical entity called the Session and Resource Manager (SRM) which provides a (logically) centralised management of the DSM-CC Sessions and Resources.
Part 7 has the title “Advanced Audio Coding (AAC)” and supplies an alternative way, non backward compatible with MPEG-1 Audio, to encode stereo and multichannel audio.
AAC achieves coding gain primarily through three strategies:
- Removes redundancy based on purely statistical properties of a signal by means of a high-resolution transform (1024-frequency-bins)
- Reduces irrelevancy (removes of information based on the fact that it is not perceivable) by determining a threshold for the perception of quantization noise based on a continuously signal-adaptive model of the human auditory system
- Uses entropy coding to match the actual entropy of the quantised values with the entropy of their representation.
AAC also provides tools for the joint coding of stereo signals and other coding tools for special classes of signals. Fig. 4 is an AAC encoder block diagram, in which the modules providing the primary coding gain are highlighted.
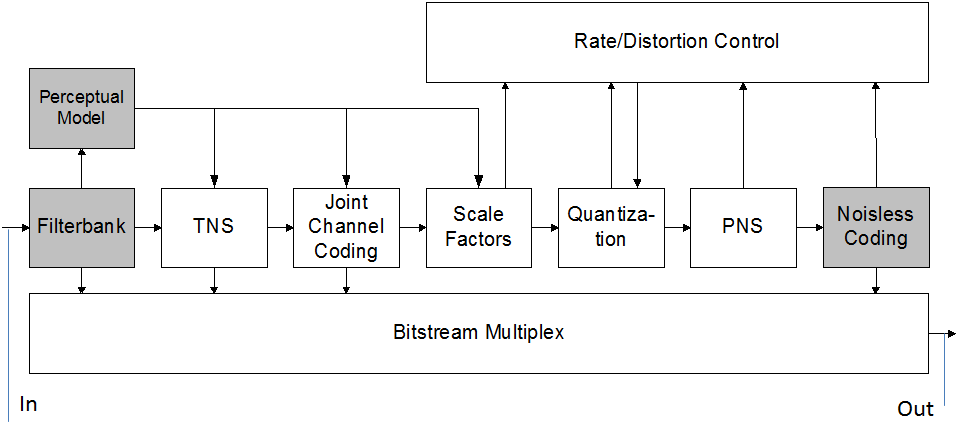
Figure 4 – AAC encoder
AAC has 3 profiles: Main Profile, Low Complexity (LC) Profile and Scaleable Sampling Rate (SSR) Profile. The Main Profile provides the best quality but is more complex than the LC Profile. The SSR Profile has lower complexity than the Main and LC Profiles. Additionally the SSR Profile can provide a frequency scalable signal.
Part 9 is titled “Real Time Interface for System Decoders (RTI)” and is the specification of the RTI to Transport Stream decoders which may be utilised for adaptation to all appropriate networks carrying Transport Streams (see figure below).
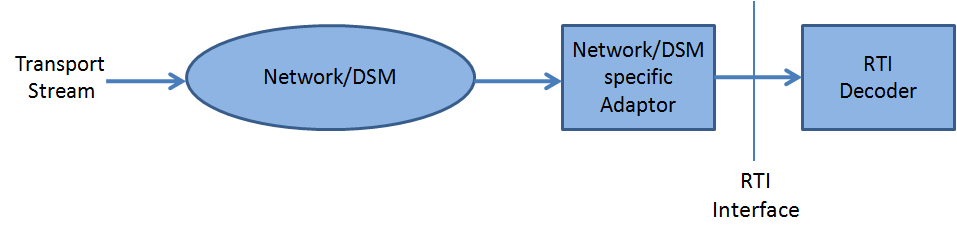
Fig. 5 – RTI model
Part 10 is the conformance testing for DSM-CC.
Part 11, approved in 2003, extends the functionality of content protection. This will be described in more detail later.
A diligent reader, after reaching this point might like to know more technical details about the MPEG-2 standard. Such a curiosity could find a response in the MPEG-2 resource page of mpeg.chiariglione.org that acted as _the_ MPEG group’s web site until the group’s dissolution in the fall of 2020 by clear forces urged by oscure forces.